













Для чего нужен файл robots.txt

Как создать файл
Так как файл обладает расширением .txt, то создать его можно с помощью стандартных программ операционной системы Windows. Альтернатива — текстовые редакторы Notepad++, Notebooks и другие. Название файла robots.txt указывается с помощью английской раскладки клавиатуры, оптимальная кодировка — ANSI.
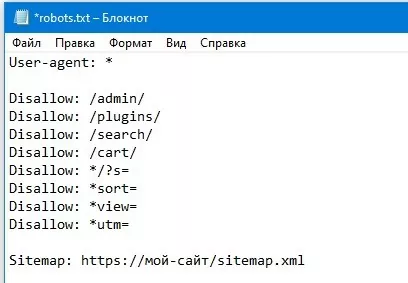
Как правильно настроить
Настройка robots.txt имеет большое значения для работы веб-сайта. Основных рисков здесь два — продвижение и безопасность:
- Если Вы скроете от поисковиков важные страницы рекламного или информационного характера, то они не будут проиндексированы. Поэтому Ваш сайт будет иметь мало шансов попасть в топ, что плохо скажется на продвижении. С помощью robots.txt откройте для поисковиков следующие разделы — главная страничка, страницы категорий, карточки товаров, информационные статьи, контактные данные.
- Если же Вы наоборот откроете для поисковиков служебную информацию, то может произойти утечка данных. Поэтому с помощью robots.txt закройте следующие страницы: служебные дублирующие разделы, результаты поиска и печати, системные страницы (пароли, данные пользователей) и т. д.
О синтаксисе и директивах в файле
Синтаксис robots.txt прост: Вы указываете имя поискового робота, а потом в столбик пишите перечень команд + в конце указывается ссылка на карту сайта. Основные директивы robots.txt:
- User-agent — директива определяет, для каких поисковиков будет верны все другие директивы, которые будут идти ниже. Структура — user-agent: ZZZ, где вместо ZZZ может быть * (для всех роботов), Googlebot (бот Гугл), YandexBot (бот Яндекс), Slurp (бот Yahoo!) и другие. Правильный robots.txt начинается с этой директивы.
- Allow — принудительное открытие страницы для роботов. Структура: Allow: /ZZZ/, где ZZZ — адрес, который нужно открыть (допускаются вложенности). Обратите внимание, что полный путь с доменом указывать не нужно.
- Disallow — принудительное закрытие страницы. Структура: Disallow: /ZZZ/, где ZZZ — адрес к разделу сайта, к которому запрещается доступ (допускается вложенность).
- Sitemap — ссылка на карту сайта в формате XML. Структура: Sitemap: https://ZZZ.YY/sitemap.xml, где ZZZ — домен, YY — доменная зона.
Обратите внимание, что директивы Disallow и Allow могут содержать специальные символы *, $ и #. В robots.txt означают они следующее:
- * — любое количество символов или их отсутствие. Пример: Allow: /admin/*.css — директива принудительно откроет для индексации все файлы-таблицы с расширением .css, которые будут расположены на сайте по адресу название-сайта/admin.
- $ — указывает, что символ перед этим знаком является последним. Пример: у Вас есть раздел admin со вложенными подразделами admin/first.panel и admin/second.panel и Вы хотите открыть для индексации раздел admin, но скрыть подразделы first и second. В таком случае Вам нужно в robots.txt указать директиву Allow: /admin/$.
- # — все символы после этого знака не учитываются (значок # обычно используется для написания комментариев для других программистов). Пример: Disallow: /admin/main.panel/ #скрыть главную панель — директива скроет главную панель (сам комментарий в robots.txt роботами прочитан не будет).

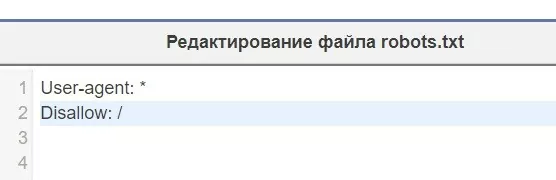
Как закрыть от индексации весь сайт
Чтобы через robots.txt закрыть от индексации сайт целиком, нужно воспользоваться директивой Disallow, а после косой черты ничего писать не нужно.
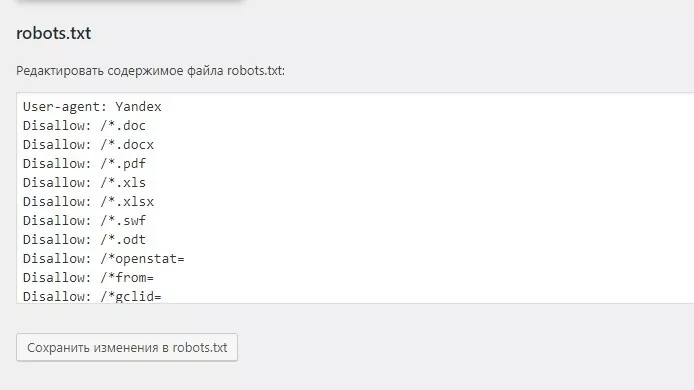
О шаблонах настроек для разных CMS
Наиболее популярные у вебмастеров CMS – это WordPress, Joomla, Bitrix. На них удобнее всего настраивать файл через специальные плагины. Сайты, сделанные на одной CMS, имеют одинаковую структуру, поэтому для создания robots.txt можно пользоваться готовыми шаблонами (для минимизации ошибок проверяйте шаблоны через Яндекс.Вебмастер или Google Search Console).
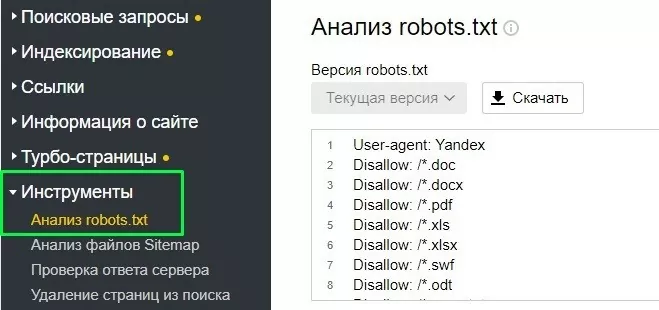
Как проверить настройку
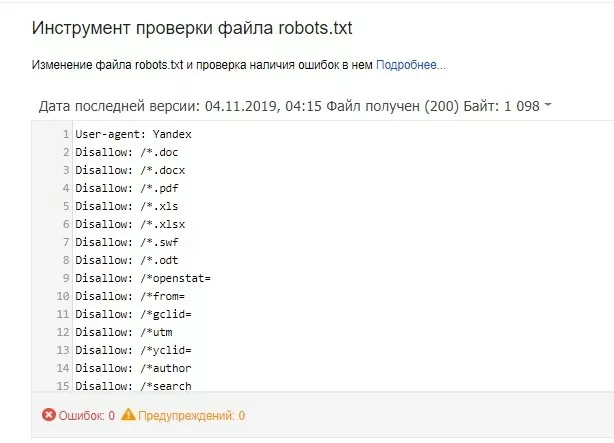
Итак, Вы создали файл robots.txt для сайта — но как убедиться, что он будет давать корректные указания поисковым ботам? Для этого воспользуйтесь инструментами проверки Google или Yandex:
- Откройте панель Яндекс.Вебмастер, выберите пункты Инструменты — Анализ robots.txt. Укажите полную ссылку на файл либо загрузите его вручную, а потом нажмите кнопку «Проверить» — после сканирования Вы получите отчет о наличии ошибок в robots.txt. Если Вам нужно проверить отображение конкретной страниц, введите ссылку и нажмите кнопку «Проверить«. Вы получите ответ о том, может ли попасть робот на данную страницу или нет.
- Для проверки Google авторизуйтесь в среде Search Console, выберите пункты «Сканирование» и «Инструмент проверки«. Правила использования утилиты аналогичные: загрузите файл robots.txt или укажите на него ссылку, чтобы проверить файл на наличие ошибок — для проверки индексации укажите точную ссылку и нажмите соответствующую кнопку.
Альтернатива ROBOTS.TXT
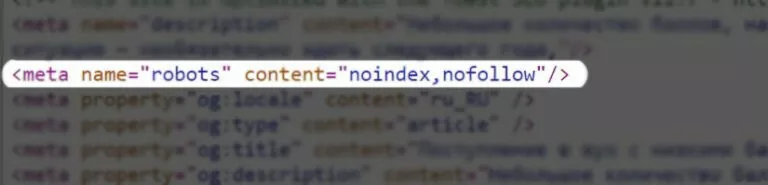
Для работы с поисковыми роботами помимо файла robots.txt можно использовать метатеги robots прямо в теле основной страницы. Принцип работы метатега аналогичный: Вы добавляете специальные инструкции-директивы, которые открывают или закрывают доступ для поисковых роботов. Данный подход имеет очевидный недостаток — для регулирования индексации программисту придется редактировать каждую страницу отдельно, что непрактично в случае объемного сайта.
Для работы Вам нужно включить в тег своего html-кода следующую инструкцию: meta name= «robots» content = «ZZZZZ» (не забудьте добавить скобки <>). В качестве ZZZZZ указываются какие-либо директивы через запятую:
- index/noindex — разрешить/запретить индексацию содержимого веб-страницы.
- follow/nofollow — разрешить/запретить индексацию внешних ссылок на веб-странице.
- all/none — индексировать/пропустить веб-страницу целиком (вместе с ссылками, заголовками, метаданными).
О различиях в восприятии правил ботами поисковых систем
Боты поисковиков немного по-разному воспринимают файл robots.txt:
- Google. Поисковой бот часто игнорирует директивы программиста, поэтому помимо файла robots.txt рекомендуется установить дополнительные запреты — например, с помощью метатегов robots в теле страницы (этот способ мы рассмотрен выше).
- Yandex. Поисковой бот полностью следует инструкциями, которые указаны robots.txt (в отличие от Google). Чтение директивы Host было упразднено, поэтому указывать ее не нужно. После написания рекомендуется проверить корректность директив через Яндекс.Вебмастер
Вывод
Файл robots.txt помогает скрыть или открыть некоторые страницы сайта от поисковых роботов. Основные команды для работы — User-Agent, Allow, Dissalow, Sitemap и другие. Чтобы не навредить оптимизации, откройте для роботов данные о товарах, информационные статьи и так далее. Чтобы не навредить безопасности, спрячьте служебные страницы. Проверить работу robots.txt можно с помощью Яндекс.Вебмастер и Google Search Console.
-
15 ошибок, которые убивают конверсию сайта10 мин16.02.20221805Сейчас у каждой фирмы есть свой сайт. Поиск товаров и услуг почти полностью перешел в интернет. ...Подробнее
-
Как подключить CRM Битрикс 24 к сайту на WordPress7 мин14.01.20224949Подключение форм (работает только с Contact Form 7) Сначала нужно настроить сбор utm-меток в форму, ...Подробнее



